Join Our Community










Get the earliest access to hand-picked content weekly for free.
Spam-free guaranteed! Only insights.
Join Our Community
Get the earliest access to hand-picked content weekly for free.
Spam-free guaranteed! Only insights.

🎯 Quick Impact Summary
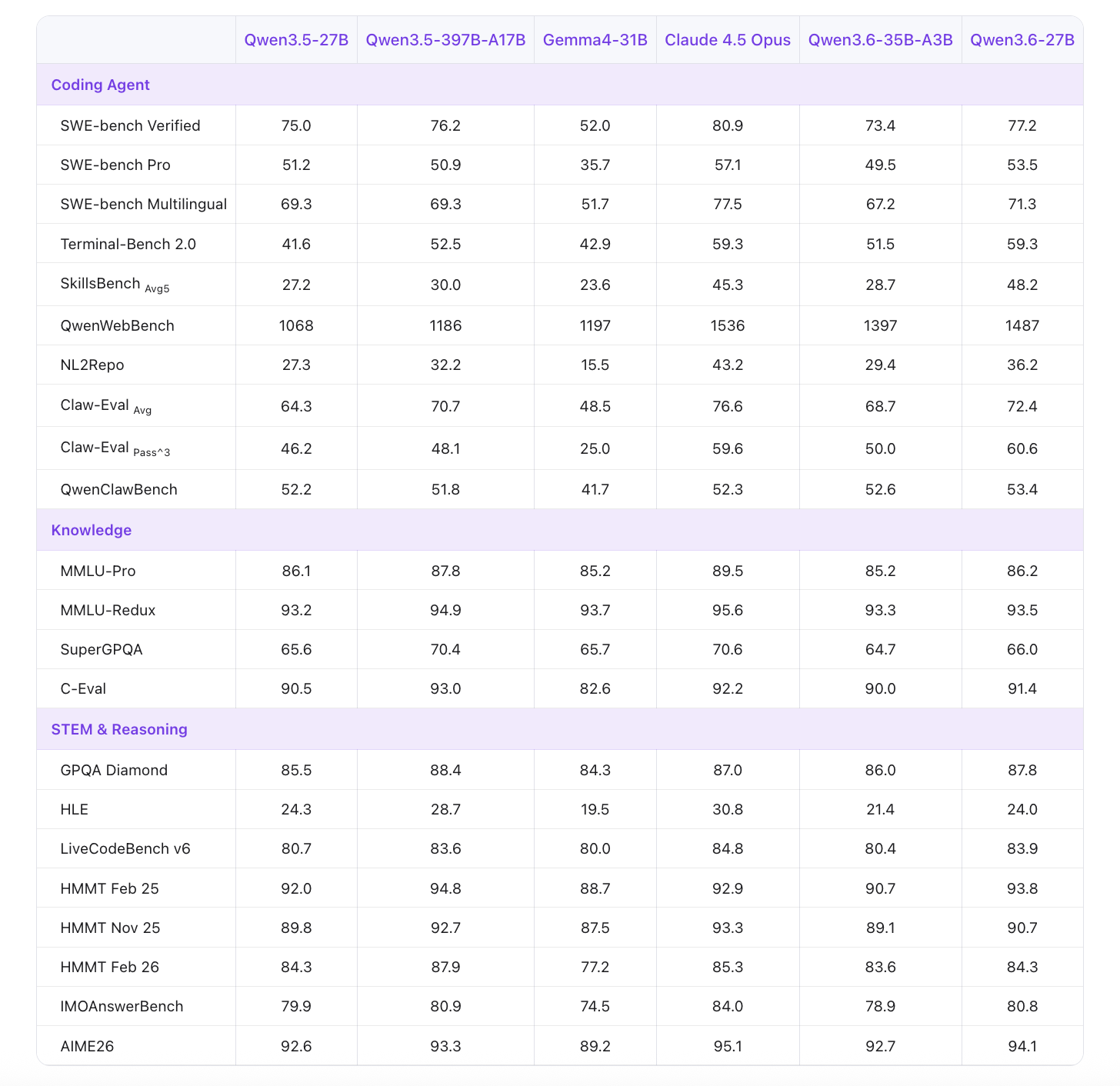
Alibaba's Qwen3.6-27B represents a significant efficiency breakthrough in large language models, delivering performance that rivals models 15 times its size on agentic coding benchmarks. This open-weight dense model combines Gated DeltaNet linear attention with traditional self-attention, introducing a novel Thinking Preservation mechanism that fundamentally changes how AI agents approach complex coding tasks. For developers, researchers, and AI teams, this means enterprise-grade coding capabilities without the computational overhead of massive mixture-of-experts systems.
Alibaba's Qwen team has delivered a dense model architecture that challenges conventional wisdom about model scaling. The 27-billion-parameter design achieves remarkable efficiency gains through innovative architectural choices and training methodologies.
Agentic Coding Excellence: Outperforms 397B mixture-of-experts models on coding agent benchmarks, delivering superior performance at a fraction of the computational cost and parameter count.
Thinking Preservation Mechanism: A novel training approach that maintains reasoning quality during inference, allowing the model to preserve and leverage intermediate thinking steps for more accurate code generation and problem-solving.
Hybrid Attention Architecture: Combines Gated DeltaNet linear attention with traditional self-attention, optimizing both computational efficiency and contextual understanding for complex coding scenarios.
Dense Open-Weight Design: Fully open-source weights enable researchers and developers to fine-tune, customize, and deploy the model without proprietary restrictions or licensing constraints.
Optimized for Agent Workflows: Purpose-built for autonomous coding agents that require multi-step reasoning, tool use, and iterative problem-solving capabilities.
Reduced Inference Latency: The dense architecture eliminates routing overhead inherent in mixture-of-experts systems, enabling faster response times for real-time coding applications.
The technical foundation of Qwen3.6-27B reflects careful engineering decisions that prioritize both capability and efficiency in the context of agentic coding tasks.
Model Size: 27 billion dense parameters with no mixture-of-experts routing, enabling straightforward deployment and predictable computational requirements across hardware configurations.
Attention Mechanism: Hybrid architecture combining Gated DeltaNet linear attention for efficient long-context processing with traditional self-attention for precise token relationships and coding syntax understanding.
Training Framework: Built on Alibaba's Qwen3.6 foundation with specialized optimization for agentic reasoning, tool use, and multi-turn code generation workflows.
Inference Efficiency: Eliminates MoE routing overhead, reducing memory footprint and enabling deployment on consumer-grade GPUs and edge devices compared to 397B parameter alternatives.
Context Window: Supports extended context lengths necessary for processing large codebases and maintaining conversation history in multi-step coding agent interactions.
Outperforms 397B mixture-of-experts models on agentic coding benchmarks, delivering superior results at 1/15th the parameter count and significantly reduced computational requirements.
Enables deployment on standard GPU infrastructure without requiring specialized hardware or distributed computing setups, reducing infrastructure costs by up to 80% compared to large MoE alternatives.
Open-weight architecture allows organizations to fine-tune models on proprietary codebases, creating domain-specific coding agents without vendor lock-in or API dependencies.
Faster inference latency through dense architecture eliminates routing delays, supporting real-time coding assistance and interactive agent workflows that require sub-second response times.
Thinking Preservation mechanism improves code quality and reasoning accuracy by maintaining intermediate reasoning steps, resulting in fewer errors and better multi-step problem-solving in complex coding tasks.
What Each Feature Actually Means:
Agentic Coding Excellence: Your AI coding agent can now handle complex multi-file refactoring tasks, API integration challenges, and architectural decisions with the reasoning capability of much larger systems. A startup can deploy a production-grade code review agent on a single GPU instead of requiring distributed infrastructure.
Thinking Preservation Mechanism: When your model generates code, it retains its reasoning process, making debugging easier and improving consistency. If an agent needs to fix a bug in generated code, it understands why it made the original decision and can iterate more intelligently.
Hybrid Attention Architecture: The model efficiently processes entire GitHub repositories or large documentation files while maintaining precise understanding of syntax and logic. This means better context awareness when generating code that must integrate with existing systems.
Dense Open-Weight Design: Your team can run this model on your own servers, fine-tune it on your proprietary codebase, and never worry about API rate limits or vendor changes. A financial services firm can create a specialized model trained on their internal coding standards without exposing code to external services.
Reduced Inference Latency: Real-time code completion, instant refactoring suggestions, and interactive debugging become practical. Developers get immediate feedback instead of waiting seconds for responses, dramatically improving the coding experience.
Before
Organizations needed either expensive API calls to large closed models or had to deploy massive 397B parameter mixture-of-experts systems requiring specialized infrastructure, distributed computing setups, and significant operational overhead. Smaller teams couldn't afford enterprise-grade coding AI capabilities, and those who could faced vendor lock-in, privacy concerns with proprietary models, and unpredictable latency in production environments.
After
With Qwen3.6-27B, teams deploy a fully open-weight model on standard GPU infrastructure that outperforms much larger systems on coding tasks. Organizations maintain complete control over their models, can fine-tune on proprietary code without external exposure, and achieve faster inference with predictable performance characteristics and dramatically lower operational costs.
📈 Expected Impact: Organizations can reduce AI infrastructure costs by 75-80% while improving coding agent performance and maintaining full model control and customization capabilities.
Use Case: Researchers use Qwen3.6-27B to study efficiency-performance tradeoffs in large language models, investigating how dense architectures with hybrid attention mechanisms can match or exceed mixture-of-experts performance on specialized tasks like code generation and agentic reasoning.
Key Benefit: Access to a fully open-weight model enables reproducible research, ablation studies, and architectural experimentation without proprietary constraints, accelerating advancement in efficient model design and agentic AI systems.
Workflow Integration: Researchers can integrate Qwen3.6-27B into benchmarking pipelines, compare it against other dense and MoE models, and publish findings on efficiency improvements in deep learning architectures and reasoning capabilities.
Skill Development: Working with this model develops expertise in hybrid attention mechanisms, Thinking Preservation techniques, and evaluating agentic reasoning quality, skills increasingly critical in modern AI research.
Publication Opportunities: The model's novel architecture and performance characteristics provide rich material for research papers on model efficiency, agentic AI, and architectural innovations in generative AI.
Use Case: Data scientists leverage Qwen3.6-27B to build custom coding agents, automated data pipeline generation, and intelligent data quality analysis tools that understand complex data transformation logic and can write production-ready code.
Key Benefit: The open-weight model enables fine-tuning on domain-specific data science tasks, creating specialized agents for SQL generation, data validation, and exploratory data analysis without relying on external APIs or closed models.
Workflow Integration: Data scientists incorporate Qwen3.6-27B into MLOps pipelines for automated code generation, integrate it with data warehouses for intelligent query optimization, and use it for documentation and code review automation.
Skill Development: Working with this model builds expertise in prompt engineering for data science tasks, fine-tuning large language models on domain-specific datasets, and deploying AI agents in production data environments.
Cost Efficiency: Running the model locally or on internal infrastructure eliminates per-token API costs, making it economical to deploy coding agents across entire data science teams and projects.
Use Case: While Qwen3.6-27B is primarily optimized for code generation and agentic reasoning, 3D modelers may use it to generate Python scripts for procedural modeling, automate Blender or Maya scripting tasks, and create intelligent tools for 3D asset generation workflows.
Key Benefit: The model can generate complex Python code for 3D modeling libraries and automation scripts, reducing manual scripting work and enabling non-programmers to create sophisticated 3D generation pipelines through natural language prompts.
Workflow Integration: 3D modelers integrate Qwen3.6-27B as a code generation assistant within their modeling software, using it to generate shader code, rigging scripts, and procedural generation algorithms that would otherwise require specialized programming knowledge.
Skill Development: Exposure to AI-assisted code generation helps 3D modelers develop basic programming literacy and understand how to leverage AI tools for technical automation, even if their primary focus remains visual and creative work.
Practical Limitation: The model's optimization for general coding means it may not specialize in 3D-specific domains as much as general-purpose coding tasks, making it a useful but not essential tool for this role.
Official Repository: Access Qwen3.6-27B through Alibaba's official Hugging Face repository or GitHub, where model weights, documentation, and implementation guides are publicly available.
Model Download: Download the 27B parameter weights directly to your local infrastructure or cloud environment; the open-weight format supports standard transformer frameworks and inference engines.
Hardware Requirements: Deploy on systems with minimum 60GB VRAM for full precision inference, or 30GB VRAM using quantization techniques like 4-bit or 8-bit precision without significant performance degradation.
Framework Support: Compatible with popular inference frameworks including vLLM, Ollama, LM Studio, and standard Hugging Face transformers library for maximum flexibility and integration options.
For Beginners:
Download Qwen3.6-27B weights from Hugging Face using git lfs clone or direct download, ensuring you have sufficient storage space for the full model.
Install required dependencies including transformers, torch, and your chosen inference framework (vLLM recommended for optimal performance).
Run a simple inference test using provided example prompts to verify installation and generate your first code output.
Experiment with system prompts optimized for coding tasks, adjusting temperature and top-p parameters to match your use case requirements.
For Power Users:
Set up quantization using GPTQ or AWQ to reduce memory footprint to 15-20GB VRAM while maintaining 95%+ performance on coding benchmarks.
Fine-tune the model on your proprietary codebase using LoRA (Low-Rank Adaptation) or full fine-tuning, requiring 2-4 days on a single GPU for meaningful domain specialization.
Implement custom inference pipelines with batching, caching, and optimization for your specific agentic workflow, including tool-use integration and multi-turn conversation management.
Deploy using vLLM with tensor parallelism across multiple GPUs for production-scale inference, achieving throughput of 100+ tokens per second per GPU.
Integrate with your existing development infrastructure using REST APIs, gRPC, or direct Python bindings for seamless incorporation into CI/CD pipelines and coding agent systems.
Quantization Strategy: Use 4-bit quantization for deployment on consumer GPUs without sacrificing more than 2-3% performance on coding tasks, dramatically reducing infrastructure requirements and costs.
Prompt Engineering: Structure prompts with explicit reasoning steps and tool descriptions to maximize the Thinking Preservation mechanism's effectiveness for complex multi-step coding problems.
Fine-tuning Focus: If fine-tuning, concentrate on domain-specific coding patterns and your organization's architectural conventions rather than general coding knowledge, yielding 30-40% improvement in task-specific performance.
Batch Processing: For non-real-time applications, batch multiple coding requests together to achieve 3-5x throughput improvement and reduce per-request latency overhead.
FAQ
AI Spotlights
Unleashing Today's trailblazer, this week's game-changers, and this month's legends in AI. Dive in and discover tools that matter.

Claude Fable 5 Review: Mythos Power with Safety

Gemma 4 12B Review: Multimodal AI on Your Laptop

Google Dreambeans Review: AI Cartoon Stories

NVIDIA Nemotron 3 Ultra: 550B MoE LLM Review

Meta AI Agent for Enterprises: Global Launch

Gemini Omni and 3.5: Google's Latest AI Models

Step 3.7 Flash Review: 198B MoE Vision-Language Model

Gemini Spark Review: Google's AI Agent Goes Personal

Microsoft Agent Governance Toolkit Review

Gemini Spark AI Agent Review: Always-On Automation

MAI-Thinking-1 Review: Microsoft's Advanced Reasoning AI

Microsoft Scout Review: OpenClaw-Powered AI Assistant

Microsoft MDASH Review: 100+ AI Agents for Threat Hunting

Google Phone App Fake Call Detection Review

Stable Audio 3 Review: Fast AI Audio Generation

Claude Opus 4.8: Dynamic Workflows & Faster AI

Microsoft 365 Copilot Redesign: 2x Speed Boost

Perplexity Bumblebee: AI Supply Chain Security Scanner

AWS OpenSearch Serverless Review: Enterprise Search Reimagined

OSCAR: 2-Bit KV Cache Quantization for LLMs
You Might Like These Latest News
All AI NewsStay informed with the latest AI news, breakthroughs, trends, and updates shaping the future of artificial intelligence.
Microsoft Patches Zero-Day After Researcher Disclosure
Jun 10, 2026
NVIDIA GPUs Power Apple's Private Cloud Compute Expansion
Jun 10, 2026
GM Launches Vehicle-to-Grid Tech to Power AI Data Centers
Jun 10, 2026
Alphabet's $85B AI Investment Signals Major Shift
Jun 5, 2026
AI Cognitive Fatigue: Work Smarter, Not Harder
Jun 5, 2026
Nvidia Unveils Physical AI Research with Cosmos 3
Jun 5, 2026
Airbnb CEO Launches AI Lab to Build Custom LLMs
Jun 5, 2026
Anthropic's IPO Filing Balances Growth With Responsible AI
Jun 3, 2026
Meta's AI Chatbot Exploited to Hijack Instagram Accounts
Jun 3, 2026
Discover the top AI tools handpicked daily by our editors to help you stay ahead with the latest and most innovative solutions.









