Join Our Community










Get the earliest access to hand-picked content weekly for free.
Spam-free guaranteed! Only insights.
Join Our Community
Get the earliest access to hand-picked content weekly for free.
Spam-free guaranteed! Only insights.
🎯 Quick Impact Summary
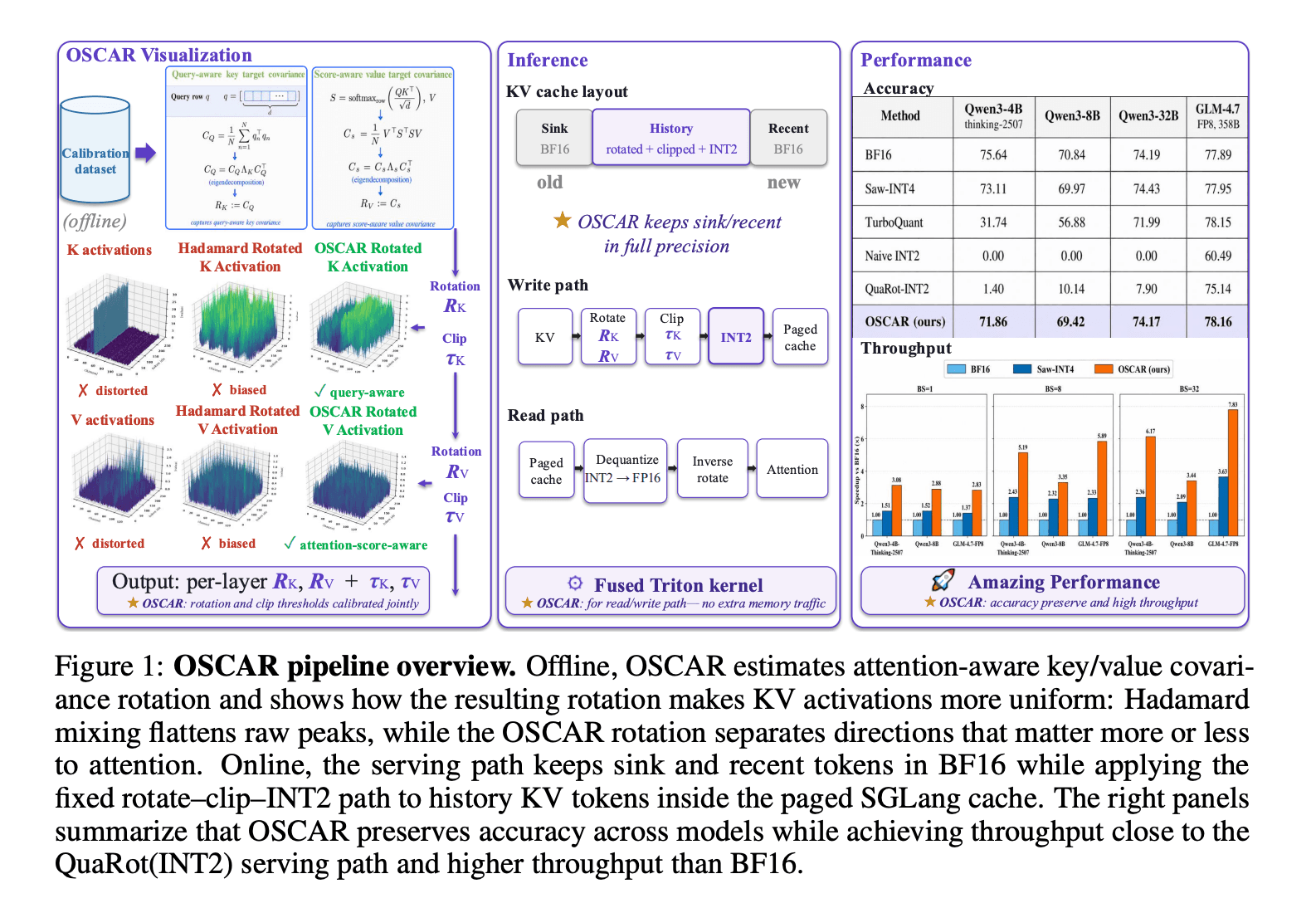
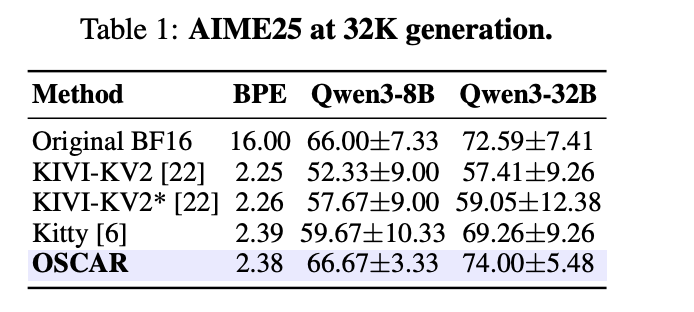
Together AI has open-sourced OSCAR, a game-changing KV cache quantization method that compresses key-value tensors to just 2 bits while maintaining near-baseline accuracy. By using attention-aware covariance structures instead of generic transforms, OSCAR achieves an 8× memory reduction and up to 3× decode speedup at 100K context lengths, making long-context LLM serving dramatically more efficient and cost-effective.
OSCAR (Offline Spectral Covariance-Aware Rotation) represents a fundamental shift in how KV cache quantization works for long-context language models. Rather than applying generic data-oblivious transforms, this system learns attention-specific rotation patterns offline to preserve the most critical information.
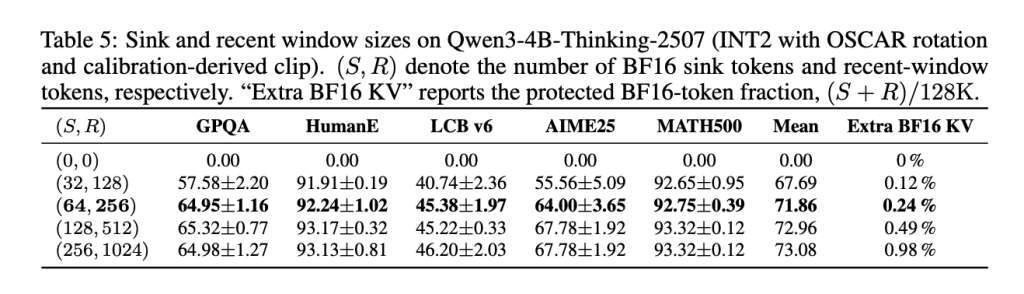
OSCAR implements sophisticated quantization through attention-aware spectral analysis and offline rotation computation. The system operates at the infrastructure level, optimizing how transformer models store and retrieve cached key-value pairs during inference.
What Each Feature Actually Means:
Before
Long-context LLM serving required massive GPU memory, with KV cache consuming 50-70% of total memory at 100K context lengths. Organizations either limited context windows to fit available hardware, invested in expensive high-memory GPUs, or accepted slow batch processing. Serving long-context models at scale was economically prohibitive for most companies.
After
With OSCAR, the same long-context workloads fit on standard GPUs with 8× less memory while running 3× faster. Organizations can now serve 100K-token contexts efficiently on existing infrastructure, enabling new applications like long-document analysis, extended conversation history, and multi-turn reasoning without hardware upgrades.
📈 Expected Impact: Production LLM serving costs drop by 60-75% while latency improves by 3×, making long-context AI accessible to organizations without specialized infrastructure budgets.
For Beginners:
For Power Users:
FAQ
AI Spotlights
Unleashing Today's trailblazer, this week's game-changers, and this month's legends in AI. Dive in and discover tools that matter.

Claude Fable 5 Review: Mythos Power with Safety

Gemma 4 12B Review: Multimodal AI on Your Laptop

Google Dreambeans Review: AI Cartoon Stories

NVIDIA Nemotron 3 Ultra: 550B MoE LLM Review

Meta AI Agent for Enterprises: Global Launch

Gemini Omni and 3.5: Google's Latest AI Models

Step 3.7 Flash Review: 198B MoE Vision-Language Model

Gemini Spark Review: Google's AI Agent Goes Personal

Microsoft Agent Governance Toolkit Review

Gemini Spark AI Agent Review: Always-On Automation

MAI-Thinking-1 Review: Microsoft's Advanced Reasoning AI

Microsoft Scout Review: OpenClaw-Powered AI Assistant

Microsoft MDASH Review: 100+ AI Agents for Threat Hunting

Google Phone App Fake Call Detection Review

Stable Audio 3 Review: Fast AI Audio Generation

Claude Opus 4.8: Dynamic Workflows & Faster AI

Microsoft 365 Copilot Redesign: 2x Speed Boost

Perplexity Bumblebee: AI Supply Chain Security Scanner

AWS OpenSearch Serverless Review: Enterprise Search Reimagined
You Might Like These Latest News
All AI NewsStay informed with the latest AI news, breakthroughs, trends, and updates shaping the future of artificial intelligence.
Microsoft Patches Zero-Day After Researcher Disclosure
Jun 10, 2026
NVIDIA GPUs Power Apple's Private Cloud Compute Expansion
Jun 10, 2026
GM Launches Vehicle-to-Grid Tech to Power AI Data Centers
Jun 10, 2026
Alphabet's $85B AI Investment Signals Major Shift
Jun 5, 2026
AI Cognitive Fatigue: Work Smarter, Not Harder
Jun 5, 2026
Nvidia Unveils Physical AI Research with Cosmos 3
Jun 5, 2026
Airbnb CEO Launches AI Lab to Build Custom LLMs
Jun 5, 2026
Anthropic's IPO Filing Balances Growth With Responsible AI
Jun 3, 2026
Meta's AI Chatbot Exploited to Hijack Instagram Accounts
Jun 3, 2026
Discover the top AI tools handpicked daily by our editors to help you stay ahead with the latest and most innovative solutions.









