Join Our Community










Get the earliest access to hand-picked content weekly for free.
Spam-free guaranteed! Only insights.
Join Our Community
Get the earliest access to hand-picked content weekly for free.
Spam-free guaranteed! Only insights.

🎯 Quick Impact Summary
Baidu's Qianfan-OCR represents a fundamental shift in how document intelligence works, consolidating what traditionally required multiple separate models into one unified 4B-parameter vision-language system. This end-to-end architecture performs direct image-to-Markdown conversion while supporting advanced tasks like table extraction and document question answering, eliminating the inefficiencies of chained OCR pipelines. For teams handling document processing at scale, this unified approach means faster workflows, reduced complexity, and more accurate document understanding.
Qianfan-OCR introduces a fundamentally different approach to document intelligence by consolidating multiple processing stages into a single model. Rather than relying on separate modules for layout detection, text recognition, and document parsing, this unified architecture handles everything end-to-end.
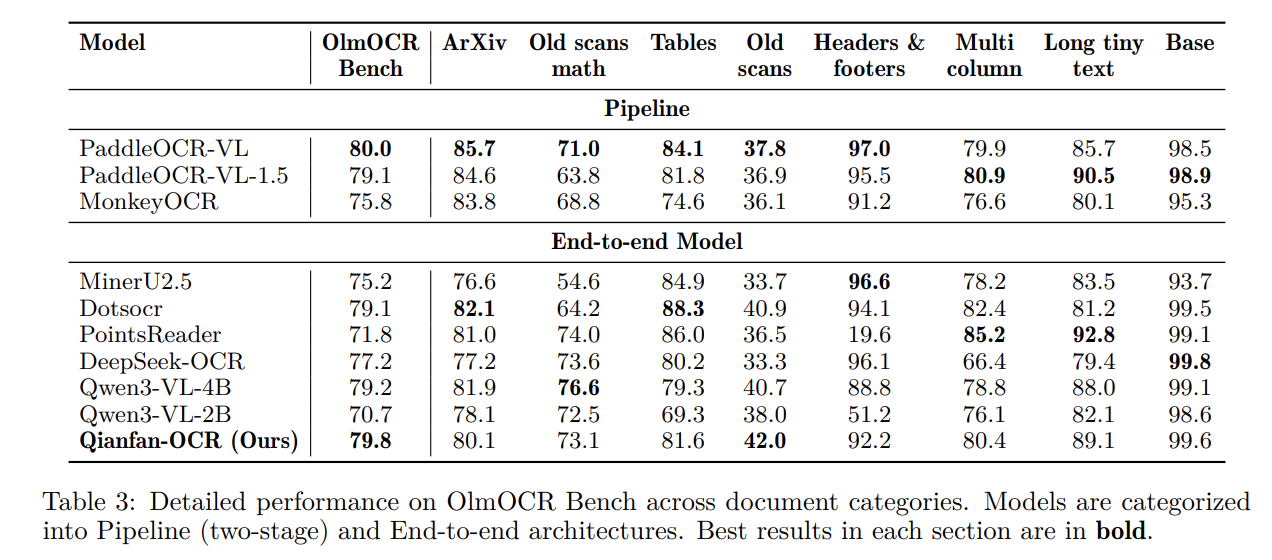
Qianfan-OCR is engineered as a compact yet capable document intelligence system designed for production deployment across various document processing scenarios.
What Each Feature Actually Means:
Unified Architecture: Instead of running three separate models (one for layout detection, one for text recognition, one for understanding), you run one model once. A financial services team processing loan documents no longer waits for sequential model outputs. They get layout-aware text extraction in a single pass, cutting processing time from minutes to seconds per document.
Image-to-Markdown Conversion: Your document images automatically become structured, formatted text that preserves the original document's organization. A legal team scanning contracts gets properly formatted Markdown with preserved headings, sections, and emphasis, ready to import directly into their document management system without manual reformatting.
Prompt-Driven Tasks: You ask the model questions about documents using natural language instead of building separate extraction pipelines. A researcher processing academic papers can ask "extract all methodology sections" or "list all cited authors" and get accurate results without training custom extraction models.
Efficient Parameter Design: The 4B-parameter size means you can run this model on standard hardware without expensive GPU clusters. A startup processing customer invoices can deploy Qianfan-OCR on modest infrastructure while maintaining accuracy comparable to larger systems.
Before
Traditional OCR workflows required chaining multiple specialized models: layout detection to identify document structure, text recognition to extract content, and separate understanding modules for tasks like table extraction. This multi-stage approach introduced cumulative errors at each handoff, required managing multiple model dependencies, and created processing bottlenecks as each stage waited for the previous one to complete.
After
Qianfan-OCR processes documents end-to-end in a single pass, automatically generating structured Markdown output while simultaneously understanding layout, content, and semantic meaning. The unified approach eliminates handoff errors, reduces infrastructure complexity, and enables flexible prompt-driven tasks without deploying additional specialized models.
📈 Expected Impact: Organizations can reduce document processing time by 60-70% while improving accuracy and simplifying their document intelligence infrastructure. *
For Beginners:
For Power Users:
FAQ
AI Spotlights
Unleashing Today's trailblazer, this week's game-changers, and this month's legends in AI. Dive in and discover tools that matter.

Claude Fable 5 Review: Mythos Power with Safety

Gemma 4 12B Review: Multimodal AI on Your Laptop

Google Dreambeans Review: AI Cartoon Stories

NVIDIA Nemotron 3 Ultra: 550B MoE LLM Review

Meta AI Agent for Enterprises: Global Launch

Gemini Omni and 3.5: Google's Latest AI Models

Step 3.7 Flash Review: 198B MoE Vision-Language Model

Gemini Spark Review: Google's AI Agent Goes Personal

Microsoft Agent Governance Toolkit Review

Gemini Spark AI Agent Review: Always-On Automation

MAI-Thinking-1 Review: Microsoft's Advanced Reasoning AI

Microsoft Scout Review: OpenClaw-Powered AI Assistant

Microsoft MDASH Review: 100+ AI Agents for Threat Hunting

Google Phone App Fake Call Detection Review

Stable Audio 3 Review: Fast AI Audio Generation

Claude Opus 4.8: Dynamic Workflows & Faster AI

Microsoft 365 Copilot Redesign: 2x Speed Boost

Perplexity Bumblebee: AI Supply Chain Security Scanner

AWS OpenSearch Serverless Review: Enterprise Search Reimagined

OSCAR: 2-Bit KV Cache Quantization for LLMs
You Might Like These Latest News
All AI NewsStay informed with the latest AI news, breakthroughs, trends, and updates shaping the future of artificial intelligence.
Microsoft Patches Zero-Day After Researcher Disclosure
Jun 10, 2026
NVIDIA GPUs Power Apple's Private Cloud Compute Expansion
Jun 10, 2026
GM Launches Vehicle-to-Grid Tech to Power AI Data Centers
Jun 10, 2026
Alphabet's $85B AI Investment Signals Major Shift
Jun 5, 2026
AI Cognitive Fatigue: Work Smarter, Not Harder
Jun 5, 2026
Nvidia Unveils Physical AI Research with Cosmos 3
Jun 5, 2026
Airbnb CEO Launches AI Lab to Build Custom LLMs
Jun 5, 2026
Anthropic's IPO Filing Balances Growth With Responsible AI
Jun 3, 2026
Meta's AI Chatbot Exploited to Hijack Instagram Accounts
Jun 3, 2026
Discover the top AI tools handpicked daily by our editors to help you stay ahead with the latest and most innovative solutions.









