Join Our Community










Get the earliest access to hand-picked content weekly for free.
Spam-free guaranteed! Only insights.
Join Our Community
Get the earliest access to hand-picked content weekly for free.
Spam-free guaranteed! Only insights.

🎯 Quick Impact Summary
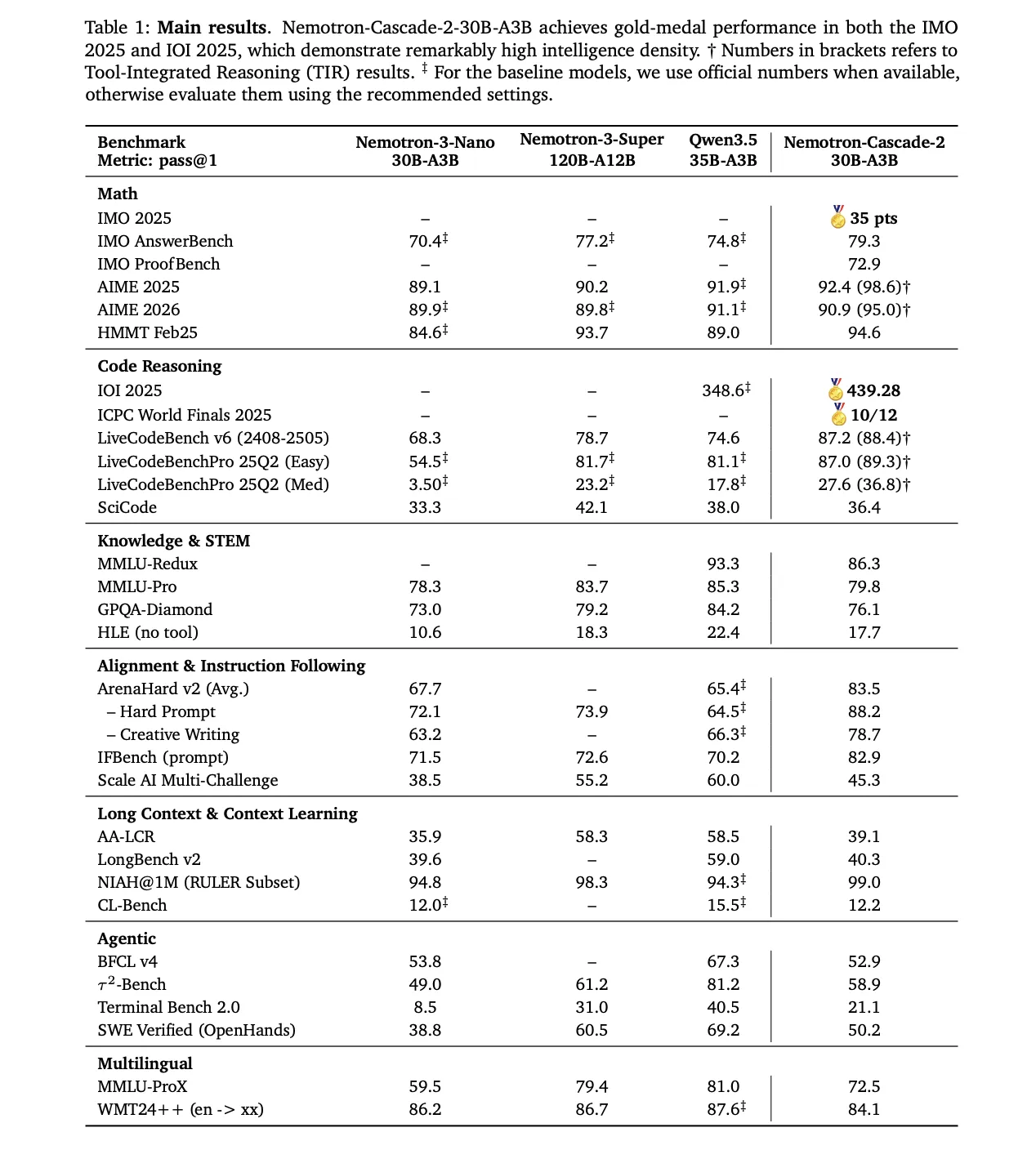
NVIDIA's Nemotron-Cascade 2 represents a major leap in efficient AI reasoning, achieving Gold Medal-level performance with a 30B parameter Mixture-of-Experts architecture that activates only 3B parameters at inference time. This open-weight model fundamentally changes the economics of deploying advanced reasoning capabilities, making enterprise-grade AI accessible to organizations without unlimited compute budgets. The release signals a shift toward intelligence density over raw parameter count, opening new possibilities for agentic AI systems and reasoning-heavy applications.
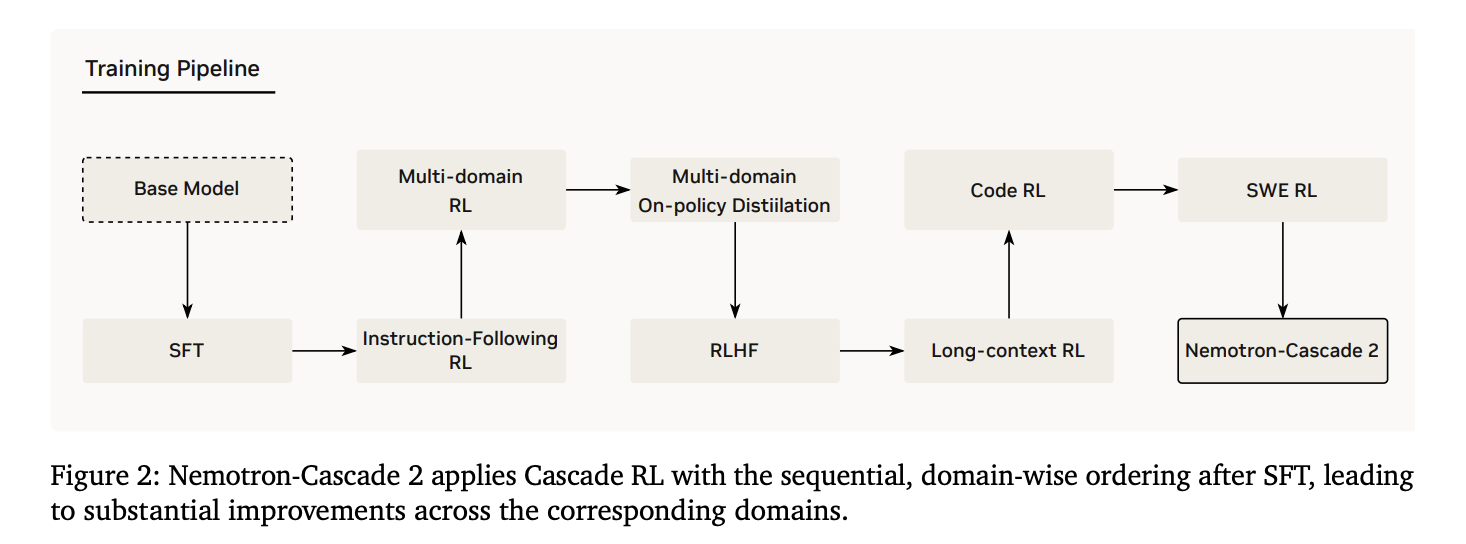
Nemotron-Cascade 2 introduces a fundamentally different approach to large language model architecture, prioritizing efficiency without sacrificing reasoning capability. This model represents NVIDIA's commitment to democratizing advanced AI by proving that smaller, smarter architectures can compete with massive frontier models.
30B Parameter Mixture-of-Experts Architecture: The model uses a sparse MoE design where only 3B parameters activate per inference, dramatically reducing computational requirements while maintaining reasoning depth comparable to much larger models.
Gold Medal-Level Reasoning Performance: Achieved second open-weight model status to reach Gold Medal performance in 2025 benchmarks, demonstrating advanced reasoning capabilities for complex problem-solving tasks.
Optimized for Agentic Capabilities: Built specifically for agent-based workflows where models need to reason through multi-step tasks, make decisions, and interact with external tools and APIs.
Open-Weight Release: Fully open-source model available for commercial and research use, enabling developers to fine-tune, deploy on-premises, and integrate into custom applications without licensing restrictions.
Intelligence Density Focus: Maximizes reasoning output per parameter, delivering capabilities previously requiring 70B+ parameter models in a fraction of the size.
Efficient Inference Economics: Reduced memory footprint and computational requirements enable deployment on consumer-grade GPUs and cost-effective cloud infrastructure.
Nemotron-Cascade 2 is engineered for production deployment with specifications designed for real-world efficiency and scalability across diverse hardware environments.
Model Size: 30B total parameters with 3B active parameters per token, achieving 90% parameter reduction during inference compared to dense models of equivalent capability.
Architecture Type: Sparse Mixture-of-Experts (MoE) with optimized routing mechanisms designed for NVIDIA GPU acceleration and compatible with standard transformer inference frameworks.
Supported Frameworks: Compatible with vLLM, Ollama, LM Studio, and major inference engines; deployable via Hugging Face Transformers with standard quantization support (GPTQ, AWQ, GGUF).
Memory Requirements: Approximately 15-20GB VRAM for full precision inference, 8-12GB with quantization, enabling deployment on consumer RTX 4090, professional A100, and cloud GPU instances.
Context Window: Extended context support for multi-document reasoning and complex agentic workflows requiring sustained reasoning across longer input sequences.
3x More Efficient Than Dense Alternatives: Delivers comparable reasoning to 70B+ dense models while requiring only 3B active parameters, reducing inference latency and memory consumption.
Cost-Effective Deployment: Enables running advanced reasoning on single consumer GPUs or modest cloud instances, reducing infrastructure costs by 60-70% compared to frontier model deployment.
Faster Inference Speed: Sparse activation reduces computation per token, enabling real-time agent responses and interactive applications impossible with larger models.
Production-Ready Agentic AI: Purpose-built for tool use, planning, and multi-step reasoning required by autonomous agent systems and complex workflow automation.
Open-Source Flexibility: Full model weights enable fine-tuning for domain-specific tasks, on-premises deployment for data privacy, and custom optimization for specialized use cases.
What Each Feature Actually Means:
Mixture-of-Experts Sparse Activation: Instead of using all 30B parameters for every query, the model intelligently routes each token through only 3B parameters. In practice, this means a financial analyst running sentiment analysis on 10,000 earnings reports processes them 3x faster and uses 70% less GPU memory than with traditional dense models, completing overnight batch jobs in hours.
Gold Medal Reasoning Performance: The model can handle complex multi-step reasoning tasks like debugging code, analyzing medical case studies, or solving mathematical proofs at the same quality level as much larger models. A data scientist using this for exploratory analysis gets reasoning quality comparable to Claude or GPT-4 but can run it locally without API costs or latency.
Agentic Capabilities: The model excels at planning sequences of actions, deciding when to call external tools, and reasoning about outcomes. An AI researcher building an autonomous research assistant can deploy this model to autonomously search databases, retrieve papers, synthesize findings, and generate reports without constant human intervention.
Open-Weight Architecture: You own the model weights completely, enabling deployment in air-gapped environments, fine-tuning on proprietary datasets, and integration into commercial products without licensing fees. A healthcare organization can fine-tune this on patient data, deploy it on internal servers, and build diagnostic assistance tools without cloud dependencies or data privacy concerns.
Efficient Inference Economics: The reduced computational footprint transforms what's economically viable to deploy. A startup building an AI-powered customer service platform can run this model on modest infrastructure, keeping per-query costs under $0.001 while maintaining reasoning quality, making profitable unit economics possible at scale.
Before
Organizations needing advanced reasoning capabilities faced a difficult choice: deploy massive 70B+ parameter models requiring expensive infrastructure, high latency, and significant operational complexity, or settle for smaller models with limited reasoning depth. Open-source options were either too small for complex reasoning or too large for cost-effective deployment. Agentic AI systems required either expensive API access to frontier models or compromises on reasoning quality.
After
Nemotron-Cascade 2 enables organizations to deploy Gold Medal-level reasoning on modest hardware at a fraction of previous costs. The sparse MoE architecture means inference latency drops dramatically while memory requirements become manageable on consumer-grade GPUs. Developers can now build sophisticated agentic systems, reasoning-heavy applications, and autonomous workflows with open-source models they control completely.
📈 Expected Impact: Organizations can reduce AI infrastructure costs by 60-70% while improving inference speed by 3x and gaining full control over model deployment and customization.
Use Case: 3D modelers can leverage Nemotron-Cascade 2 for AI-assisted design workflows, using the model's reasoning capabilities to interpret design briefs, suggest modeling approaches, and automate repetitive geometry generation tasks within 3D applications.
Key Benefit: The model's agentic capabilities enable autonomous tool use within 3D software, allowing modelers to describe complex scenes or structures and have the AI reason through optimal modeling strategies without manual intervention.
Workflow Integration: Integrate via APIs into Blender, Maya, or custom pipelines to generate procedural content, optimize mesh topology, or suggest design improvements based on project requirements.
Skill Development: Working with this model helps 3D modelers understand AI-assisted creative workflows, prompt engineering for design tasks, and how to structure design briefs for AI interpretation.
Practical Application: A character modeler describes "a weathered medieval knight in full plate armor" and the model reasons through optimal topology, suggests reference materials, and generates modeling guidelines, reducing pre-production planning time.
Use Case: AI researchers use Nemotron-Cascade 2 as a baseline model for studying efficient architectures, sparse MoE mechanisms, reasoning capabilities in smaller models, and agentic behavior in open-weight systems.
Key Benefit: The open-weight model enables direct access to architecture details, weights, and internals for research, eliminating API-based limitations and enabling novel experiments in model compression, fine-tuning, and reasoning analysis.
Workflow Integration: Download weights from Hugging Face, integrate with research frameworks (PyTorch, JAX), fine-tune on custom datasets, and publish findings without licensing restrictions or closed-model constraints.
Skill Development: Researchers deepen expertise in MoE architectures, sparse model design, reasoning evaluation methodologies, and efficient inference optimization techniques.
Practical Application: A researcher studying how models reason through multi-step problems fine-tunes Nemotron-Cascade 2 on specialized reasoning benchmarks, analyzes activation patterns across expert layers, and publishes findings on intelligence density optimization.
Use Case: Data scientists deploy Nemotron-Cascade 2 for reasoning-heavy analytics tasks including anomaly detection reasoning, complex data interpretation, automated feature engineering suggestions, and multi-step data pipeline reasoning.
Key Benefit: The efficient architecture enables running advanced reasoning on local machines or modest cloud infrastructure, eliminating dependency on expensive API services and enabling real-time reasoning within data workflows.
Workflow Integration: Integrate via Python libraries into Jupyter notebooks, data pipelines, and analytics platforms; use for automated data quality analysis, pattern discovery, and generating hypotheses from complex datasets.
Skill Development: Data scientists develop expertise in prompt engineering for analytical tasks, integrating LLMs into data workflows, and leveraging reasoning models for exploratory data analysis and insight generation.
Practical Application: A data scientist analyzing customer churn patterns uses the model to reason through multi-variable interactions, suggest feature engineering approaches, and interpret complex statistical relationships, accelerating analysis cycles from days to hours.
Download from Hugging Face: Visit the official Nemotron-Cascade 2 repository on Hugging Face Model Hub where weights are available under open-source licensing.
Choose Your Inference Framework: Select from vLLM for high-throughput serving, Ollama for local desktop use, LM Studio for GUI-based deployment, or Transformers for research and custom integration.
Prepare Your Hardware: Ensure you have 15-20GB VRAM for full precision or 8-12GB with quantization; compatible with NVIDIA GPUs (RTX 4090, A100, H100) and cloud providers (AWS, Azure, GCP).
Configure Quantization (Optional): Apply GPTQ or AWQ quantization to reduce memory footprint by 50% if deploying on consumer hardware or cost-sensitive environments.
For Beginners:
Download Ollama from ollama.ai and install on your machine (Mac, Linux, or Windows with WSL).
Run ollama pull nemotron-cascade-2 to download the model (approximately 15GB).
Start the local server with ollama serve and access via http://localhost:11434 or use the Ollama chat interface.
Begin querying the model with reasoning tasks like "Analyze this dataset and suggest three optimization approaches" to experience its reasoning capabilities.
For Power Users:
Clone the official repository and install dependencies: pip install transformers torch vllm for production inference serving.
Load the model with custom configurations: AutoModelForCausalLM.from_pretrained("nvidia/Nemotron-Cascade-2", load_in_8bit=True) for quantized inference.
Set up vLLM server for high-throughput production: python -m vllm.entrypoints.openai_api_server --model nvidia/Nemotron-Cascade-2 --tensor-parallel-size 2 for multi-GPU deployment.
Fine-tune on domain-specific data using LoRA: python finetune.py --model_name_or_path nvidia/Nemotron-Cascade-2 --dataset your_data.json --output_dir ./finetuned_model.
Integrate into production pipelines via OpenAI-compatible API endpoints that vLLM exposes, enabling drop-in replacement for existing LLM integrations.
Leverage Sparse Activation: Structure prompts to guide the model toward specific expert pathways; detailed context and clear reasoning instructions activate relevant parameters more efficiently.
Batch Inference for Cost Optimization: Group multiple queries into batch processing to maximize GPU utilization and reduce per-query inference costs by 40-50%.
Fine-tune for Domain Expertise: Invest time in LoRA fine-tuning on domain-specific reasoning tasks; the model's efficiency makes fine-tuning economically viable even for small organizations.
Monitor Token Usage: Track active parameter activation patterns; the model's efficiency means you can run more queries per GPU hour than dense models, enabling real-time interactive applications.
FAQ
AI Spotlights
Unleashing Today's trailblazer, this week's game-changers, and this month's legends in AI. Dive in and discover tools that matter.

Claude Fable 5 Review: Mythos Power with Safety

Gemma 4 12B Review: Multimodal AI on Your Laptop

Google Dreambeans Review: AI Cartoon Stories

NVIDIA Nemotron 3 Ultra: 550B MoE LLM Review

Meta AI Agent for Enterprises: Global Launch

Gemini Omni and 3.5: Google's Latest AI Models

Step 3.7 Flash Review: 198B MoE Vision-Language Model

Gemini Spark Review: Google's AI Agent Goes Personal

Microsoft Agent Governance Toolkit Review

Gemini Spark AI Agent Review: Always-On Automation

MAI-Thinking-1 Review: Microsoft's Advanced Reasoning AI

Microsoft Scout Review: OpenClaw-Powered AI Assistant

Microsoft MDASH Review: 100+ AI Agents for Threat Hunting

Google Phone App Fake Call Detection Review

Stable Audio 3 Review: Fast AI Audio Generation

Claude Opus 4.8: Dynamic Workflows & Faster AI

Microsoft 365 Copilot Redesign: 2x Speed Boost

Perplexity Bumblebee: AI Supply Chain Security Scanner

AWS OpenSearch Serverless Review: Enterprise Search Reimagined

OSCAR: 2-Bit KV Cache Quantization for LLMs
You Might Like These Latest News
All AI NewsStay informed with the latest AI news, breakthroughs, trends, and updates shaping the future of artificial intelligence.
Microsoft Patches Zero-Day After Researcher Disclosure
Jun 10, 2026
NVIDIA GPUs Power Apple's Private Cloud Compute Expansion
Jun 10, 2026
GM Launches Vehicle-to-Grid Tech to Power AI Data Centers
Jun 10, 2026
Alphabet's $85B AI Investment Signals Major Shift
Jun 5, 2026
AI Cognitive Fatigue: Work Smarter, Not Harder
Jun 5, 2026
Nvidia Unveils Physical AI Research with Cosmos 3
Jun 5, 2026
Airbnb CEO Launches AI Lab to Build Custom LLMs
Jun 5, 2026
Anthropic's IPO Filing Balances Growth With Responsible AI
Jun 3, 2026
Meta's AI Chatbot Exploited to Hijack Instagram Accounts
Jun 3, 2026
Discover the top AI tools handpicked daily by our editors to help you stay ahead with the latest and most innovative solutions.









